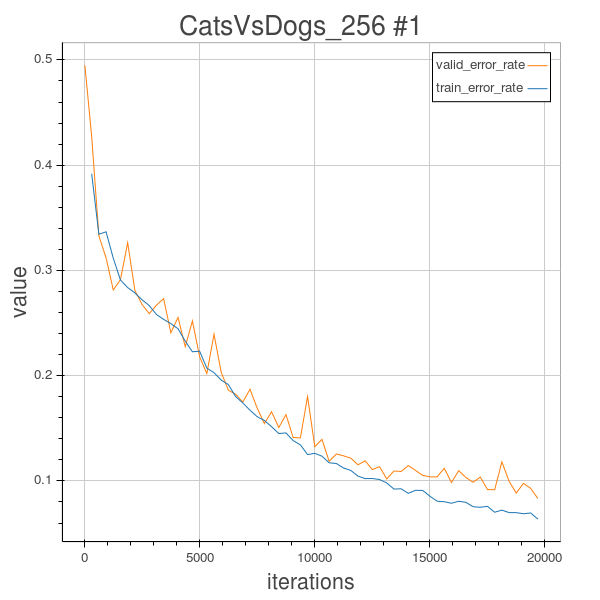
Cats and Dogs 2.3 (6 Conv layer architecture) with rotation, valid_error 8.32%
Hi,
As mentioned in Blog posts 2.2, this time, I tried to use a 6 layered CNN to conduct experiment, but with more feature maps at each layer, and at the last convolutional layer, there are 512 feature maps. More features maps might help the last MLP to better discriminate the image.
In this experiment 2.3, I still use the Random2DRotation Method to rotate each training image by a random degree, and keep their label untouched, to do regularization, so the model will learn different dogs or cats’images with different random rotated angles. However this time, I tried to set the initial learning rate for Adam() as 0.0005, rather than using its default values.
As we learned from course, initial learning rate is very important, if it is set big, the optimization will oscillate, and if it is set too big, the optimization process will diverge, it is linked with the inverse of the biggest eigenvalue of the Hessian of the cost function. However if the learning rate is chosen to be too small, the learning will be very slow, and here, as we are using Adam() to decay the learning rate as time elapses, at the end stage the learning rate will be very small can the learning cannot go on effectively.
And as tried in last experiment 2.2, I still use a learning rate of 0.0005 which seems to work well for this 6 layered architecture.
In this experiment, I’m using a 6-convolution layered CNN architecture.
The configurations are as follows:
num_epochs= 63 (at the time of posting this blog)
batch_size=64
image_shape = (256,256)
filter_sizes = [(5,5),(5,5),(5,5),(5,5),(5,5),(5,5)]
feature_maps = [20,40,70,140,256, 512]
pooling_sizes = [(2,2),(2,2),(2,2),(2,2),(2,2),(2,2)]
mlp_hiddens = [1000]
output_size = 2
weights_init=Uniform(width=0.2)
step_rule=Adam(learning_rate=0.0005)
max_image_dim_limit_method= MaximumImageDimension
dataset_processing = rescale to 256*256
Validation error=8.32% after 63 epochs.
However we can see that at 63 epochs the validation error is only a little bit lower than the 8.5% of the last experiment which has 120 feature maps at the last layer, so the enhencement caused by adding feature maps seems not that much. It is worthwile to try other regularization techniques or better optimization method to help furthur improve performance in the next experiment.