Cats and Dogs 1.2
Hi,
As mentioned in Blog posts 1.1, the fixed learning rate might not be a good choice, if it is chosen too small, the learning is to slow, and even cannot pull the cost function to a better minimum, on the other hand, if it is set too big, the loss will decrease and may oscillate and even bounces back to a higher loss as encountered in the figure of experiment 1.01… So Adam() might be a better choice.
In this experiment, I’m using the same 3-convolution layered CNN architecture as in 1 and 1.01
The configurations are as follows:
num_epochs= 100 early stopped
image_shape = (128,128)
filter_sizes = [(5,5),(5,5),(5,5)]
feature_maps = [20,50,80]
pooling_sizes = [(2,2),(2,2),(2,2)]
mlp_hiddens = [1000]
output_size = 2
weights_init=Uniform(width=0.2)
step_rule=Adam()
max_image_dim_limit_method= MaximumImageDimension
dataset_processing = rescale to 128*128
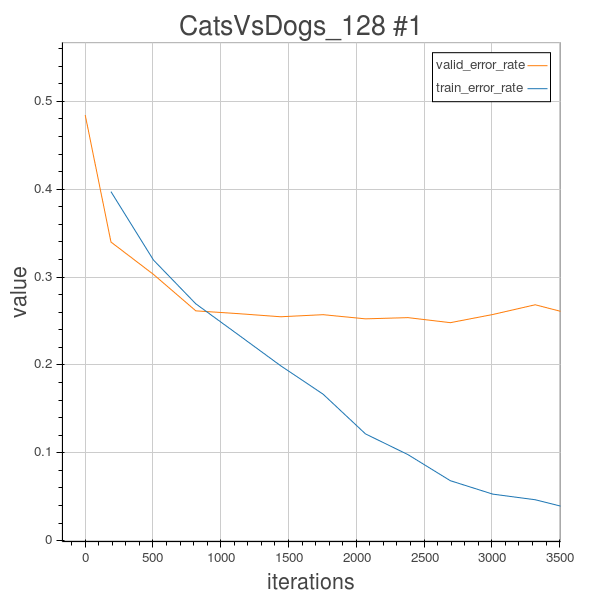
This time, we can still observe the phenomenon of overfitting, so I just stopped training at epoch 21 because the valid error no longer decreases, and stagnate at around 25% however the training error still goes down. So this architecture setting might has its limitaitons. So data augmentation is very important to avoid things like overfitting. I’ll try to use rotations transformations to regularize.
